Implementation
Learn more about the application's implementation and technical architecture.
Contents
- Python-telegram-bot for Bot-user-interactions
- Telethon for Group Handling
- Conversation Handlers
- Private chat handler
- Room handler
- Task handlers
- RoomManager
- Tasks
- SequentialTask
- Non-sequential tasks
- Outlook
- Language proficiency model
- Proficiency updates
- Task selection
- Evaluation
- Introduction
- SQL features
- Tables Created for the Project
- Database Operators for Entities
- Database Connection Class
- Entity Classes
Technical Challenges & Development Productivity
- Actual state evaluation & Goals
- Debug mode
- Rejection of Automated Testing
- Bugs
Implementation process and documentation
- First contact
- Improved Documentation
- Code conventions
- Workflow
Technical Architecture
In this section we will provide a brief overview of the technical architecture that we relied on to build our application. All of our code is hosted in a private GitHub repository which also includes a step-by-step guide on how to start the application.
In general, the structure of the implementation was inspired by the model-view-controller (MVC) software design pattern. Figure 1 gives an overview of the different application elements within this MVC design pattern. It also shows where the associated source code can be found in the repository.
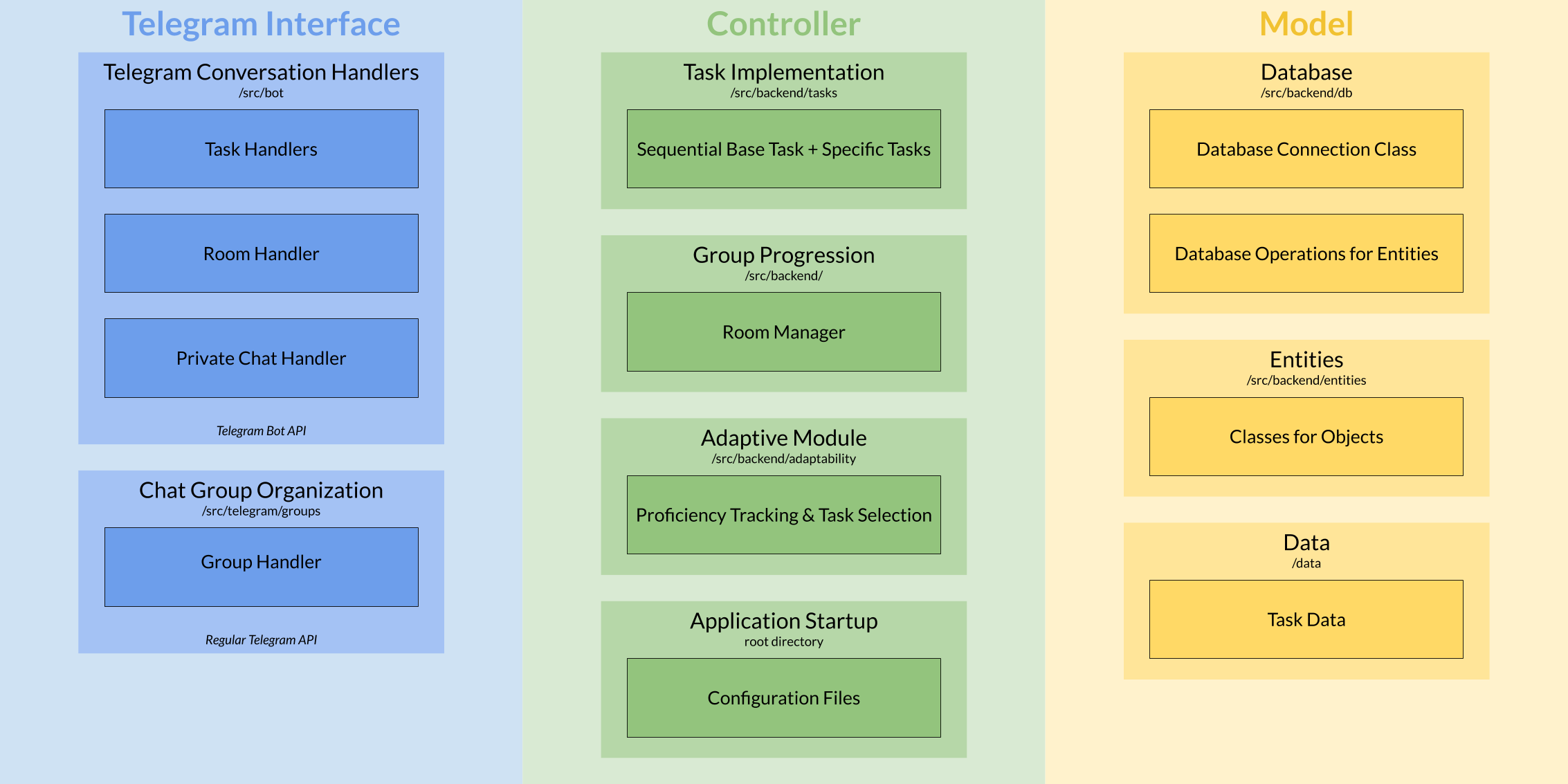
Figure 1: Overview of Repository Content
As we decided to use the Telegram application as the front-end for our application, the view element of our MVC design pattern has been reduced to an interface with two Telegram APIs. This will be further explained in the section Telegram Integration.
Concerning the programming language, we relied on Python 3. This decision was made mostly due to Python being the common denominator in the programming experience of the implementation team. Given that Python is taught and commonly used in courses of the Cognitive Science program, we also hope that this eases onboarding of new team members in future stages of the study project.
We employed an object-oriented approach to programming, especially in the controller module of our application. The Task Framework section will elaborate more on how this approach was used for the modeling of different tasks.
A cloud-hosted PostgreSQL database serves as our data storage. PostgreSQL is a free and open-source relational database management system. For now the database is hosted on a free platform but we intend to migrate to a university server in the upcoming semester. Motivation for this change is both the limited capacity of the free hosting as well as the need for more management tools such as backups.
Generally, the chosen architecture enabled us to quickly implement first task prototypes in the initial stages of the project. However, especially during later stages we found that small changes to the task design entailed quite substantial changes to the implementation. For example, changes to the task data had to be reflected at least in the database, the functions that interact with the database, and the entity that refers to this data. For the next phase of the study project, we suggest to devote more time to fine-tuning a task’s design before greenlighting it for implementation. Also, we could think about employing a holistic model of the database entities in Python using a preexisting framework such as SQLAlchemy to speed up adaptions to our data model.
Telegram Integration
This section describes the technical components of the Telegram front-end integration, including relevant handlers required to realize the application’s intended functionality.
Python-telegram-bot for Bot-user-interactions
As we decided to use a Telegram chatbot as our front-end and Python as programming language, we investigated different methods to manage the communication between the chatbot and the learning application. First, we explored the Telegram Bot API, which is a HTTP-based interface for developers that want to build bots for telegram. It is developed and maintained by Telegram itself and offers all the methods that are currently available for Telegram bots. Nevertheless, we decided not to use the Telegram Bot API directly, because we do not want to do the HTTP calls and the corresponding error handling ourselves. Therefore, we decided to use a python library that wraps the Telegram Bot API. On the Telegram Bot Code Examples site we found three Python wrapper: python-telegram-bot, pyTelegramBotAPI, and AIOgram. After a short investigation we decided to use the python-telegram-bot for the following reasons. First, it offers us all the elements of the Telegram Bot API and is actively maintained. Second, it implements a conversational handler that allows us to easily structure complex conversations. Third, the documentation is better than the documentation of the other wrappers. Last, some of the developers had already experience with it.
Telethon for Group Handling
The downside of using a Telegram bot and the Telegram Bot API is that bots are not able to create groups or invite users to groups. Thus, we had to find a way to realize this feature. After some research we found the python package Telethon. The package provides a wrapper around the standard Telegram API, which allows the creation of groups and sending invitations to users. In order to use the Telegram API with the Telethon wrapper we needed a Telegram account to get access to the Telegram API. After setting up the Telegram account and registering an application for this user, we were able to create groups and invite users to this group.
Conversation Handlers
To structure the conversations between the bot and the users we implemented different conversation handlers. A conversation handler consists of four different collections of other handlers, e.g. message handlers and command handlers. The entry points list is used to instantiate the conversation and normally contains a command handler that reacts to commands like /start sent as a message to the bot. When a user sends a message to the bot, the conversation handler tries to find a matching handler within the list of entry points. A handler matches when the message passes the specified filter of the handler. If a matching handler is found, the callback function of that handler is executed that reacts to the message of the user. Thereby the function returns a value, which determines the state of the conversation handler. The second collection is a states dictionary that maps the different states of a conversation to a list of handlers. If a message is sent to the bot while the conversation is already instantiated, the conversation handler looks for a matching handler in the list of handlers associated to the current state it is in. If no matching handler is found, the conversation handler searches for a matching handler in the fallbacks list, which is the third collection. The last collection is a dictionary called map_to_parent. It is used in nested conversation handlers to map a specific state of the nested conversation handler to a state of the parent conversation handler. This allows the transition from the nested handler back to the parent handler. Several handlers have been implemented, separated according to their concerns so that a total of seven handlers exist.
Private Chat Handler
The interaction between the bot and a user in a private chat is handled by the private chat handler. Its purpose is to register a user for the app, add the user to a group or create a group, and tell the user the beginning of the story. It can also deal with some problems that may occur when creating the group. The handler is started with the /start-command sent to the bot in a private chat. Afterwards the user is guided through the conversation by the use of reply keyboards sent to the user. Figure 2 shows the general conversation flow of the private chat handler. For simplicity, error handling is not covered in the figure.
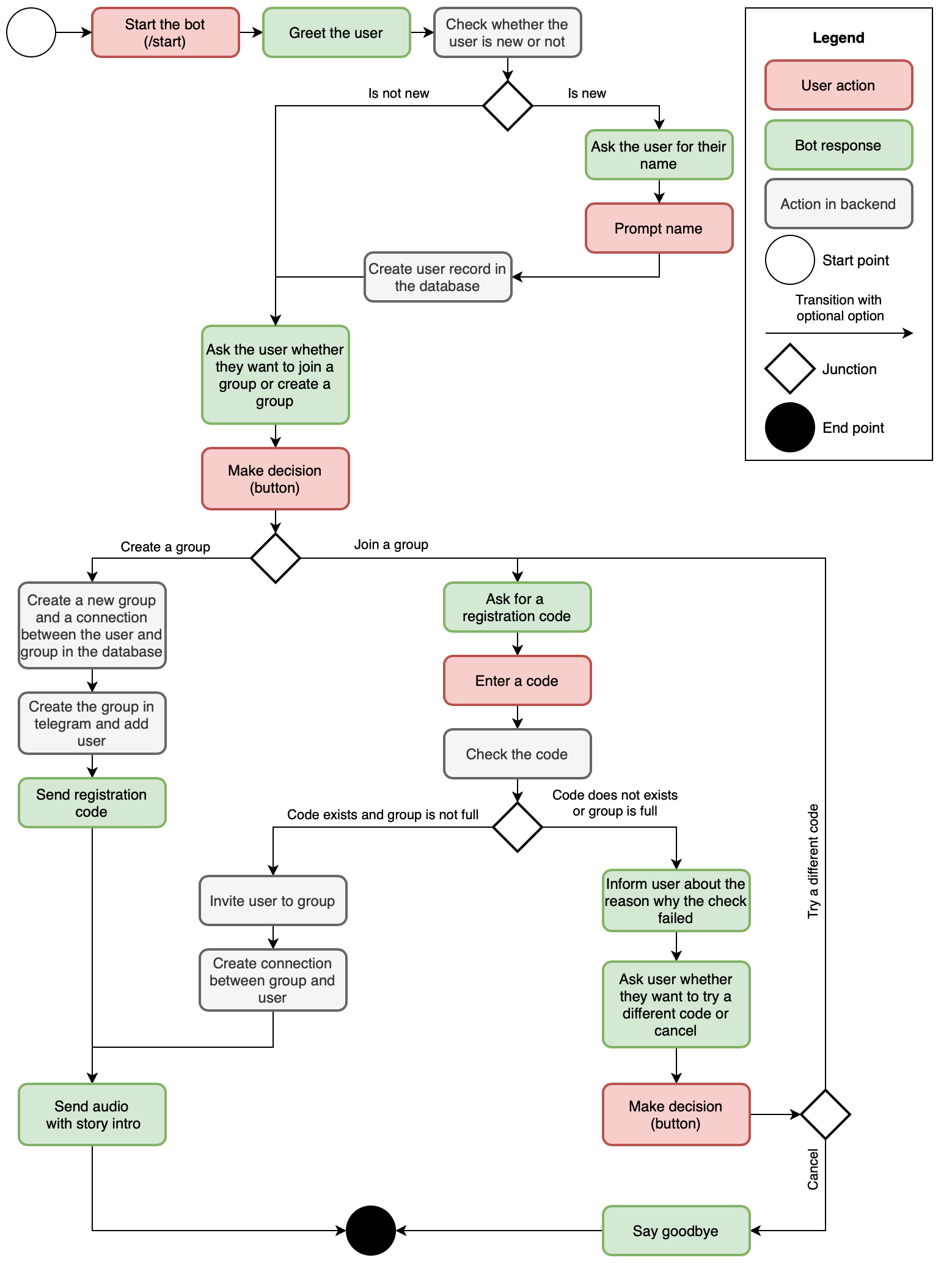
Figure 2: Conversation flow of the private chat handler including backend activities
Room Handler
The room handlers’ purpose is to lead the users from one task to the next task. This handler is also started with the /start command but only if the command is sent in a group chat. After starting the bot checks whether enough players are currently available and which tasks they can solve next. After the users have selected a task the related nested task handler is called.
Task Handlers
To handle the users interaction with the bot during the different tasks, we created a task handler for each task. The task handlers for the first two tasks (vocabulary guessing and sentence correction) lead the users in a similar way through the conversation. First, they send a message to one of the active users containing the task they have to perform. Then, the handlers wait for the response of either a group member or the selected user. The answer is evaluated upon reception. Depending on the outcome, the users can correct their answer, move on to the next subtask, or, if the task is completed, the next user is selected. This procedure is continued until the task is fully finished. After finishing the complete task, control is returned to the room handler.
The only way a task handler can be entered is through the room handler. In order to ensure that a task handler is not entered with an insufficient number of users we developed a custom filter to prevent this.
Task Framework
This section aims to explain the implementation decisions and to describe the resulting components that have been implemented for the application’s task framework.
It should be noted that this section only contains general information about the overarching task framework of our application. More details on the implementation the different tasks can be found on their respective pages:
- Vocabulary guessing task page
- Sentence correction task page
- Discussion task page
- Listening task page
In the next sections, we will cover the role and necessity of a RoomManager, as well as the structure and idea of different task classes. Lastly, this section concludes with an outlook subsection, which presents our plans for further improvements to the task framework.
RoomManager
The RoomManager is thought of as a host for the group of players. Since we decided on having some instance that controls the general task and game flow, we created the RoomManager class. Each game session gets assigned exactly one RoomManager
instance that handles the session. An object of the RoomManager class captures important meta information about the group of players, such as the number and names of active players (stored in self._full_student_list), the minimum amount of time after starting the bot (self._min_time_for_students_to_join_in_sec) , and the minimum number of players needed to start the game (self._min_number_of_students), as well as a check that all actively participating students have given their consent to start the game (can_execution_start()).
Tasks
During the design phase of our application, we were able to pin down a few requirements for the technical implementation of the tasks for our prototype. These requirements include:
- The enablement of collaborative task solving
- The ensuring of participation of each player
- An adaptive module that controls for user-specific task difficulty
- A winning condition
Since this project features several tasks, we chose to create an abstract base class Task, which then can be further expanded depending on the type of task.
The abstract base class Task(ABC) defines, through abstract methods, which minimal properties and functions every task to follow should inherit, such as getting the instructions for the respective task (get_task_instructions()). The discussion and listening tasks inherit from this class (see Non-sequential tasks).
To capture the requirements 1-4 defined above, we implemented a subclass that inherits from Task(ABC), namely the SequentialTask(Task). The vocabulary guessing and sentence correction tasks inherit from this class (see SequentialTask).
For the implementation of requirement 3 (the adaptive module) please refer to the section Adaptive Module below.
SequentialTask
SequentialTask(Task) is a subclass of Task(ABC) which in turn is a superclass of our two sequential tasks: vocabulary guessing and sentence correction. As stated above, to ensure requirements 1) and 2), we created a sequential task scaffolding. This means that each task consists of multiple rounds, in which each player takes the active role of solving the main task exactly once, during which time the other players take a slightly more passive role, e.g. by assisting the active player to solve the task. Each SequentialTask has properties such as self.all_users, self.remaining_users and self.selected_user. Those properties enable the sequential handling of a task, in which each player gets the active role at least once.
After having successfully completed a round, the group gets awarded with one piece of the codeword self.code. This code word consists of a series of random digits, the number of which corresponds to the number of rounds played. This covers the winning condition in requirement 4). Additionally, after completing the whole task, the corresponding user proficiencies and the group’s proficiencies get updated according to the performance with the call of the function update_proficiencies(correct).
Non-sequential tasks
After the first semester of work on the project, we decided that we wanted to feature a more diverse portfolio of language practice tasks, because featuring exclusively sequential tasks was proving too repetitive for the users. Therefore, we implemented the non-sequential discussion and listening tasks, which simply inherit from the abstract base class Task(ABC).
Outlook
Over the course of three semesters, our application has come to feature a diverse portfolio of language practice tasks. Significant effort has also been made to connect these tasks to our underlying escape-room narrative. Next semester, we plan on implementing further improvements to ensure that our application’s gamified and learning aspects are more seamlessly integrated with one another.
Adaptive Module
Our implementation of the adaptive module of the language learning application relies on a model of the user’s proficiency. In this section we will briefly explain the model and then dive deeper into the implementation of the model, updating user proficiency, and the adaptive selection of the next task iteration. Finally, we reflect on drawbacks of adaptive modeling approach that we have taken.
Language Proficiency Model
The hierarchical model contains two language domains on the first level that reflect the main set of skills: Grammar and vocabulary (cf. Figure 4). The sentence correction tasks focuses on grammar skills whilst the vocabulary guessing task aims to augment the users’ vocabulary. On the second level, the domains are subdivided into more granular sub-skills, e.g. relative clauses or gerunds in the grammar domain.
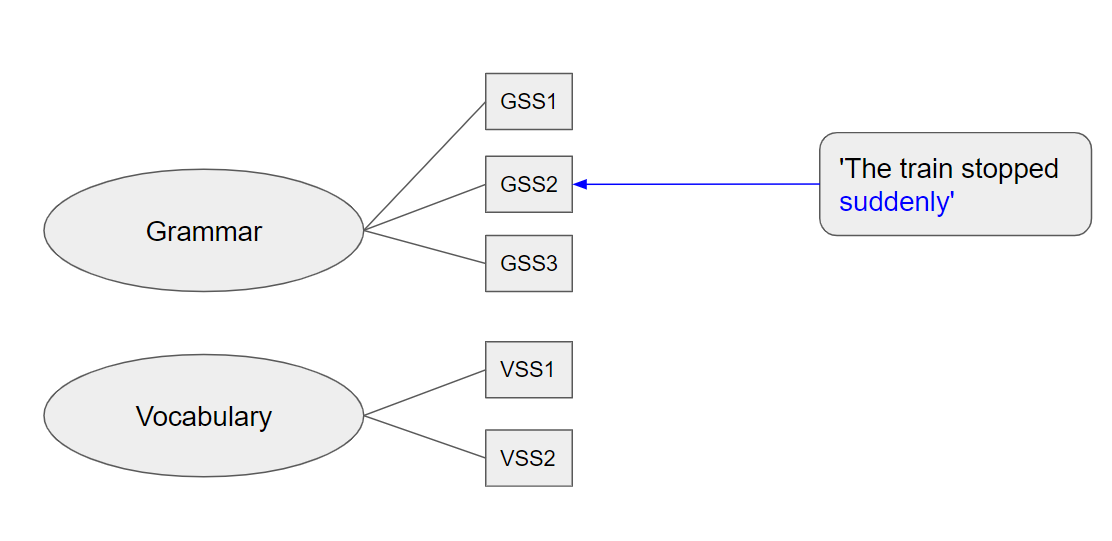
Figure 4: Graph visualization of the hierarchical difficulty model.
For each subskill there are multiple task variations of different difficulties on a three-point scale (low – medium – high). For more information on the structure of this data, see the database section.
We implemented the hierarchical structure by creating an enum for each domain that contains all sub-skills. In Python, an integer value can be assigned to each symbolic name. We chose the integers to be consistent with the values we use to specify the sub-skills in the database. This allowed us to easily retrieve task data from the database and convert the sub-skill to a member of the enum by simply calling the enum with the ID (e.g. Grammar(2) would resolve to the Grammar.TENSE enum member).
In order to adaptively navigate a task, we also need to store and change the proficiency of the users engaged in that task. Thus, each user object that we use in the backend contains an instance of the Proficiency class. This class mainly consists of two dictionaries for the language domains, where each member of the corresponding enum is used as a key and the user’s proficiency for that particular subskill is stored as the value. Additionally, the average domain proficiency is also stored as a numerical user variable for performance sake. Singular and average values range from one to ten with the former being the lowest proficiency and the latter the highest. For proficiency storage over multiple sessions, please refer to the Database section.
Proficiency Updates
When a group finishes a single task iteration, the proficiency of all users in the group is updated. The update is handled by the update_proficiencies function in the Proficiency class. This function takes a list of sub-skill enum members and updates the corresponding value based on a Boolean that indicates a correct or false answer to the task as well as another Boolean declaring a passive or active update. For passive group members we want softer updates compared to the selected active user. Thus, we use a step size of 0.25 for passive and 1.0 for active updates. In case of a correct answer, the step size is added to the proficiency and it is subtracted for an incorrect answer. We limit the result to be within our predefined range of one to ten. If a sub-skill had no value previously as the user has not yet participated in a task relevant to that sub-skill, an initial estimate of the proficiency is made based on the answer to the task. If it was correct, we estimate 7.5 as the proficiency. An incorrect response yields 2.5 as the initial proficiency estimate. After all sub-skill proficiencies have been updated, the domain averages are recalculated and stored in their respective variable.
Task Selection
For the adaptive selection of the next task iteration, two properties of the tasks have to be considered: Language sub-skill and difficulty. As we have no previous knowledge of the user’s sub-skill proficiencies, we made the choice to always prioritize tasks for unknown sub-skill proficiencies of the selected user. We randomly draw one sub-skill from a list of all keys that are without a value in the proficiency dictionary. The difficulty is always set to medium in this case. This enables us to create initial estimates of new values, as outlined in the proficiency update section above.
If all sub-skill proficiencies in the task’s domain are known for the active user, we randomly chose a sub-skill based on probability inverse to the corresponding proficiency. Thus, sub-skills that the user already excels in are selected less frequently than those the user might still need more practice with. In our implementation, we compute a draw probability based on the proficiency by subtracting the squared proficiency from 110 for each sub-skill. These probabilities are then re-normalized and used in the random.choice function of the NumPy module.
Finally, the difficulty for the selected sub-skill is based on the user proficiency of that sub-skill and the domain average of that user. For this, we compute a weighted mean between the sub-skill proficiency and the domain average. Currently, we place more emphasis on the sub-skill proficiency by weighting the average with 0.5. Task difficulty is then chosen based on this mean proficiency. A proficiency of one to three results in a low, four to seven in a medium, and eight to ten in a high difficulty. A random sentence or word with the selected sub-skill and difficulty is then loaded from the database.
Evaluation
Although we put a lot of thought into the design and implementation of the adaptive module, there is no substantiated scientific model to back it up. While studies have shown that adaptive difficulty adjustments positively impact learning (Nebel et al., 2020; Sampayo-Vargas et al., 2013), the target difficulty has to strike the balance between being easy enough to motivate and – in the context of educational games – hard enough to optimize learning outcomes. We find it unlikely that our current adaptive module strikes that balances for a number of reasons: Task difficulty is only represented on three levels that have been assigned based on intuitions. The difficulty level of the current question does not affect the update strength. We did not evaluate the perceived difficulty of tasks from users in our target group and we did not relate this to our proficiency estimates or learning outcomes.
With our current model, we also put more emphasis on language skills that are not strongly developed yet instead of fortifying existing strengths. While this serves the implicit educational goal of a good overall language knowledge, we should reassess if this is in fact the aim of our application.
At the end of the first semester it was proposed to devote more resources towards the adaptive model in the second semester of this study project. For the evaluation of the model during that time it was argued that objective measures for the actual language competency of our users would be needed in order to compare those to the calculated proficiency estimates. Moving forward from there, it was considered beneficial to track the user performance more closely depending on the sub-skill and difficulty, because this data could prove very useful in the later fine-tuning of the adaptive difficulty. During the second semester these propositions have been addressed and are documented on their own site Adaptive Module.
Database
Introduction
Given the implementation design, it is necessary to store data for efficient retrieval during application runtime. The bot deals with user data and other essential data from Telegram that we had to store, update, and retrieve in real time. As the data is relational in nature, we structured these relationships in a backend PostgreSQL database. Each table in the database contains records and attributes which may be visualized as rows and columns (cf. Figure 5).

Figure 5: Sample database table entry from the sentence correction task table.
SQL Features
SQL databases allows you to assign each column with a data type which indicates which kind of data can be stored in each column. PostgreSQL permits several data types, each with their own constraints. Table 1 summarizes the data types and constraints of the attributes represented in the aforementioned sentence correction database table.
| Column Name | Data Type | Constraints |
|---|---|---|
| id | SERIAL | PRIMARY KEY |
| sub_type | SMALLINT | NOT NULL |
| difficulty_level | SMALLINT | NOT NULL |
| sentence_corpus | TEXT | NOT NULL |
| correct_answers | TEXT ARRAY | NOT NULL |
| error_words | TEXT ARRAY | NOT NULL |
Table 1: Data types of the sentence correction data.
Table 1 mentions the constraints which limit the values that can be entered for a given attribute. Constraints are generally column specific, but some can be for the whole table. Example: PRIMARY KEY – Ensures that the values in the cells of that column are not empty or NULL and each entry is unique. Primary key is made of two constraints NOT NULL and UNIQUE.
Array represents that the column can have more than one value present. For columns like correct_answers when we have more than one possible correct answer for a given sentence, we would like to store all the possible correct answer in that one cell. Example: If the sentence is “Do you want they to help you?” the correct answer is them, but there are other correct answers which we would like to store as well.
Tables Created for the Project
Table 2 summarizes the database tables of the backend PostgreSQL database.
| Table Name | Table Description | Table Columns | Entities |
|---|---|---|---|
| group_table | Data of every group for tasks | id, chat_id, invitation_url, invitation_code, current_task_id | Group |
| student_group_table | Connecting data between student and group | student_id, group_id | |
| sentence_correction_data | Raw data of the sentence correction task | id, sub_type, difficulty_level, sentence_corpus, correct_answer, error_words | Sentence |
| vocabulary_guessing_task | Raw data of the vocabulary guessing task | id, sub_type, word, difficulty | Word |
| student_proficiency_table | Mapping of each user and their proficiency | student_id, proficiency_id, value | |
| proficiency_table | This table has the mapping of the proficiency levels and ids | proficiency_domain, proficiency_id, proficiency_name | |
| student_table | Data about each student using the bot | id, telegram_name, name | Student |
| task_table | Every task data | id, name, min_num_of_players, num_of_iteration | Task |
Table 2: Tables Names and Descriptions
Database Operators for Entities
We needed different queries to extract data based on different use cases. The following are the examples of queries with example of use cases.
- Querying data from a table. We need such kind of queries to just explore the data and check the structure of the table.
- Filtered Query based on certain columns. If you want to extract data based on a certain value from a specific column. We need such queries when we need data (sentences or word) based on certain difficulty level OR if we need the proficiency level of a particular user
- Limited Query. Limiting your output to a specific number of outputs. For example: when we need 1 random sentence from the sentence correction data.
Similar query functions are used while inserting data into specific tables, In which case one uses Insert instead of Select. The SQL insert statement helps to push the data in the database. Based on the query types above, we defined functions to parse data from the database into the corresponding Python entities. Example:get_student_proficiency returns the proficiency level of the users and get_sentence_information_from_df parses the information from the database into sentence corpus, one error word and one correct answer.
Database Connection Class
We defined a database connection class which connects with the database based on provided configuration parameters. We set the database configuration required to connect with the database in a separate source file and created a function to form this connection. Once the connection is created we can use functions like get_random_sentence_based_on_sub_type_and_difficulty, which allows the code to get a random sentence to use in the task based on the sub_type and difficulty level. Every Task is further mapped with entities to get certain data from the database. Like the sentence correction task is mapped to sentence and student entities. Its similar for the vocabulary guessing task. For more information please refer the next subsection.
One more function is created that parses the data once the connection is open. The data we query for any table is converted into a DataFrame for further use. The function to extract a DataFrame is read_query_into_df.
Entity Classes
We created classes for entities and created functions in them to get certain values from those entities. This allows one to extract a certain value from the entire object rather than extracting all relational values of the entity. We have five entities. We have already seen that Tasks are mapped to entities and each entity is mapped to a table in the database. The first entity is called Group and helps to get the group id and the chat id of the groups performing tasks. The second entity is the Sentence entity which initiates the extraction of a sentence for the task. One of the important functions in this class is is_correct, which determines whether a sentence is correct or not. We also have a function to get the proficiency level. Student is the next entity class which gives us information about the user for example, their id or name. It also helps to update their proficiency level when they complete their task. The next entity is called Task which helps to return information about the task, its id, name, minimum users required, etc. The final entity of mention is Word, which has the mapping of the word and its difficulty level.
Technical Challenges & Development Productivity
This section gives insights into the development experience and challenges to develop a telegram chatbot application for a group learning experience. Hindrances that slowed down the development process are highlighted and solutions that improve the development productivity are presented. Finally, bugs and their corresponding fixes are described as well as an outlook for future development.
Actual state evaluation & Goals
To get familiar with the project and evaluate the inherited state of the application the new constellation of study project members in the third semester played the game themselves. This was done in three groups of three people each. During these game sessions, it was noticeable that the application is in an unstable condition because multiple bugs occurred that hinder the progression of the game. For example, after solving all of the current tasks the players are supposed to receive a code word to enter the next room. Either this code word was not received or the prompt to enter the code word did not appear, ultimately resulting in a deadlock state that can only be recovered by restarting the bot and thereby starting all over again. Sometimes the application even crashed entirely. Consequently, one goal for the semester was the elimination of any bugs that hinder a successful play-through of the game. Another goal was to improve the development productivity. It was noticeable that playing through the game takes a lot of time, which can slow down the playtesting of newly introduced code changes, e.g. changes at the very end of the game. Additionally, it was not possible to play the game by oneself. From a user experience perspective, this makes sense, as the game is meant to be a learning experience for groups, but from a development perspective, this hinders productivity. Most of the developers had to pair up in groups of two because only one telegram account can be registered per mobile phone number and they only own one. Therefore, a so-called debug mode was newly implemented to better these circumstances.
Debug mode
This debug mode allows a developer to play through the vocabulary guessing and sentence correction task much faster because only one iteration is played instead of three. This means instead of the usual three required answers per group member, only one answer is required. In addition, the discussion task is accelerated by shortening the duration in which answers are allowed. Moreover, hints or solutions to the task at hand are now printed to the console, so that a progression through the tasks takes less effort and eventual incorrect utterances of the bot can be spotted more easily. Also, the sentence correction task can be played by a single developer in the debug mode. The debug mode can be activated by a developer by setting a debug option in the bot config file to true. All in all, the new debug mode reduced the time of a full play-through of the game from around 30 minutes to 10 minutes.
Rejection of Automated Testing
To address the known bugs mentioned above, one approach would have been the adoption of automated tests. Unfortunately, the structure of the given codebase was not implemented with automated testing in mind. Also, setting up a testing suite itself in the context of telegram bot development is not trivial. Getting familiar with bot testing tools and rewriting the whole project would have taken a lot of time. Even if done in smaller chunks this was estimated to take away too much time that could be better spent on new features or other improvements. Therefore, setting up and implementing automated tests has been discarded entirely.
Bugs
During this semester the most notable bugs have been found and fixed so that the game can be completed successfully. Surprisingly, one severe bug could be fixed by simply appending parentheses to the statement sentence_task.is_success. Without the parentheses, python evaluates this statement as a reference to the function object is_success instead of calling the function with is_success(). Despite the elimination of such bugs, every so often there still occur errors that lead to a crash of the application in the worst case. For example, when too many or too long messages are sent in fast succession a telegram.error.RetryAfter: Flood control exceeded error occurs. Furthermore, during a bad internet connection, a telegram.error.NetworkError can occur or when no messages have been sent for a longer period of time a special case of the NetworkError the telegram.error.TimedOut can happen.
To understand the cause of these errors it is necessary to grasp the underlying architecture of the telegram bot which is already described in the Telegram Integration section. Just as a short reminder, the python-telegram-bot library is a wrapper that handles HTTP requests towards the Telegram Bot API. The API has some restrictions like the above-mentioned message limits that result in a response with an error status code. This error is handled by the library and passed on to be handled in the application. Handling these errors and retrying the last action would be a workaround only treating the symptoms. A better solution would be the usage of a MessageQueue. Unfortunately, the MessageQueue has four known bugs and is therefore already marked as deprecated with no release date of a replacement in sight. Additionally, it is noteworthy that such errors can happen in all sorts of places in the code making the implementation difficult. All in all, there is no clear path on how to go about these problems. It might even be a possible approach to completely rewrite the application in a different chatbot technology.
Implementation process and documentation
The study project team this semester consisted mostly of team members who are new to the project. This was the case especially for the implementation team. This yielded a number of different problems: the team had to first understand how to run the code, then understand the code design and structure and more detailed pieces of information e.g. which function should be used in which case, etc. Additionally, the team had to settle down on how to write new code and how to integrate it to the existing codebase. This implies the formulations of common code conventions and workflow. First, the team will describe the team’s first contact with the codebase and the difficulties encountered. Second, we will describe how the team decided to alleviate those difficulties for the new team members in the upcoming semester. Lastly, we will describe our workflow and the code conventions the team settled for.
First Contact
At the beginning of this semester, the previous implementation team members kindly gave a presentation about the codebase. They described its overall organization and some of the most important functions. In particular, the presentation given was a great help to understand how the Telegram API is used throughout the project. To be able to work on the code, it was key to understand how the individual tasks and chat handlers worked. The given presentation was an important step in getting familiarized with the project and its implementation. Nevertheless, the documentation at hand did not provide enough detailed descriptions to be able to read into the codebase without difficulties. Therefore, it was decided to supplement the documentation.
Improved Documentation
Initially, the documentation provided enough information about how to use and start the bot locally. Additionally, the documentation was focussed on the design choices and decisions that were made in the semester. The team was still facing the problem of lacking a pure technical documentation, which would contain all the information about files, classes, functions, global and local variables, etc.
Flow Diagrams
The previous members of the study project partially documented the codebase by describing the private conversation handler. It was described using a flow diagram, specifying the states and color coding the bot and users actions. The diagram was very detailed but not very readable.
It was decided to create the same kind of documentation for the three task handlers: the discussion task handler, the vocabulary description task handler and the sentence correction task handler. Since the bot uses deterministic states to function, each handler also follows this principle. To be readable, the team decided to make flow diagrams that are similar to a finite state automata: every state is mentioned with an individual within the diagram. The previous diagrams mentioned the states outside the flow diagram, in a table-like structure. The team also settled to document the states, individual function calls, the user’s actions and the bot’s actions using boxes and colors that are similar to the private chat handler diagram. Different branching usually due to if-conditions are described with a question and the outgoing branches describe the actions following different outcomes.
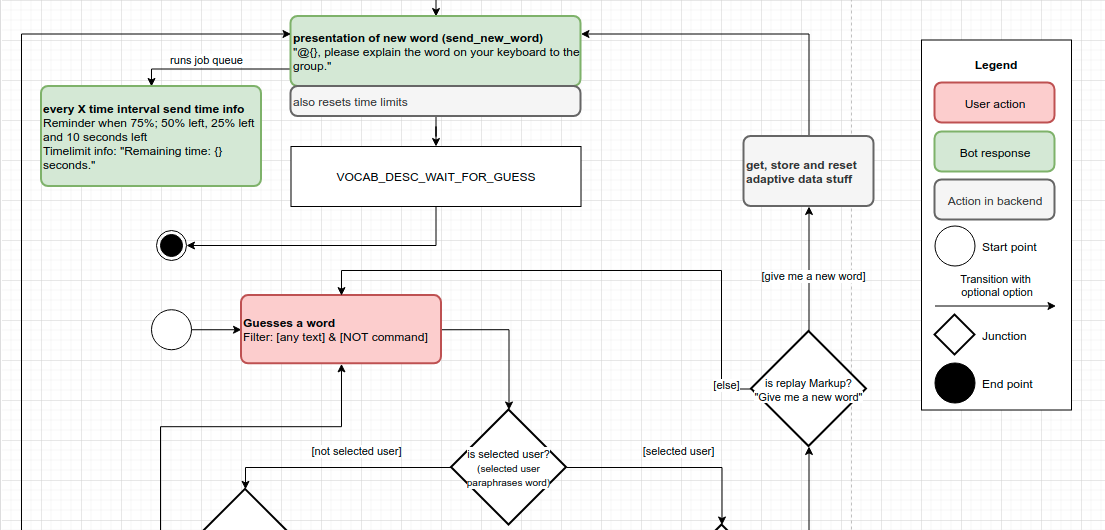
Figure 6: Detail of Vocabulary Task Handler diagram including the legend
Technical documentation
It would have been possible to generate a technical documentation automatically with the function’s doc-strings, for example by using the python package pydoc. Unfortunately, this is not possible because the functions are seldom described with doc-strings. The team decided against adding the missing doc-strings because of the project’s time constraints.
With our additional flow diagrams, we hope that new team members in the next semester have the possibility to read quicker into the codebase. This should allow a faster development process and rewarding development experience. The new task we developed still lacks its corresponding flow diagram.
Code conventions
During the familiarization with the project’s implementation, it was noticed that the previous developers did not follow some important principles of clean coding. For example, it was noted that many comments did not follow the DRY (“Don’t repeat yourself”) principle. Also, some variable names were not descriptive enough to be understood efficiently. Therefore, the team decided on code conventions which every new addition to the code should meet. This semester’s developers therefore decided to apply the PEP8 conventions, with the help of the autopep8 Python package. The team had a meeting to discuss and refresh important principles of coding for making the code more readable for other developers. This semester’s team did some refactoring of the codebase: this process will continue throughout next semester if found necessary.
Workflow
The bot’s implementation is located on a GitHub repository. The team had to decide how to proceed with editing and augmenting the codebase during the project. For every new feature or bug, independent of its scope, the developers were urged to create a new branch with a descriptive name. In case of a corresponding GitHub issue, it was favored to add the GitHub issue number for better documentation and explanation of the feature or bug. All developing processes are saved on their corresponding branches. Once finished, the developer creates a pull request to merge changes into the develop branch which another developer will review. If the reviewer requests changes, the branch is updated and corrected until the reviewers consider the task as done. The branch is then merged into develop. In a final step, reviewers check the develop branch: if everything is deemed to be correct, it is then merged into themain branch, which constitutes the code in production.
References
Nebel, S., Beege, M., Schneider, S., & Rey, G. D. (2020). Competitive Agents and Adaptive Difficulty Within Educational Video Games. Frontiers in Education, 5. https://doi.org/10.3389/feduc.2020.00129
Sampayo-Vargas, S., Cope, C. J., He, Z., & Byrne, G. J. (2013). The effectiveness of adaptive difficulty adjustments on students’ motivation and learning in an educational computer game. Computers & Education, 69, 452–462. https://doi.org/10.1016/j.compedu.2013.07.004